
Most developers analyze their system design by designing a system that keeps latency constant as throughput increases. Of course, this definition is correct, but the point is that in this regard, more attention is paid to the scaling category (focusing on horizontal scaling) and all the solutions offered are in line with this concern. And the point that always remains is the consistency and concurrency category. Many developers forget that for all software with a very serious and important problem that lurks like a hidden danger to seriously affect constancy and throughput. The name of the problem? concurrency
Now the point is that all the solutions proposed to solve this problem neutralize and make ineffective all or at least a large part of the measures taken to scale and increase throughput
But...
Wait
Is this really the case?
First, let's get on the same page about the different processing methods and techniques available
Text assumptions (important!):
- We’re talking about a monolith or single logical service with multiple instances deployed
- Goal = horizontal scaling
- No microservices / Saga discussion here (that’s a different game)
Different methods of processing requests:
1.Async processing
In this case, we only store the raw data in the database without processing and return the message "Your request has been queued for review" to the user, and we put the stored data in the queue for review and processing in order.
But since we have deployed several instances in the direction of horizontal scaling, we must be very careful about concurrency.
In general, in async processing, operations can be performed directly on the database, but we must be careful about locking the data.
2.Sync processing
If async processing is not possible in the conditions and the processing must be performed in real-time or OnDemand and the result must be returned to the user, and at the same time, we must consider scaling and concurrency together, it is better to use this formula
 Processing.png.webp)
Different techniques to try to maintain throughput and scaling while considering concurrency
1.pessimistic + row-level + SKIP LOCKED:
Lock the record pessimistically so that concurrent jobs or any other operations cannot access that record
Best use case: async processing from the database (such as job queue, event processing, batch jobs)
Example SQL:
SELECT TOP(10) * FROM Jobs WITH (UPDLOCK, ROWLOCK) WHERE status='pending’Example MySQL /PostgreSQL:
SELECT * FROM Jobs WHERE status = 'pending' FOR UPDATE SKIP LOCKED LIMIT 10
Ideal for when we have async processing and we can pessimistically lock the record and the parallel processing can move to the next row. Both concurrency is handled and the system scales (SKIP LOCKED or NOWAIT technique)
Note :
Pessimistic locking with SKIP LOCKED increases throughput in the presence of contention
Where? Whenever you have the ability to lock a record and the next process can ignore it and move to the next row
Example: Processing events from the database. Every time a job fetches rows, you lock them and the next job automatically moves to the next rows and does not need to wait
👉«pessimistic + row-level + SKIP LOCKED» is the best friend of scaling in job queues.
2.Redis + Instant Response + Async Persistence (King of Scaling): Here Redis can play an important role.
If there is a condition where you keep the information in the cache and process the response in-memory based on the input and execute the processing later in the form of sending a message to a broker, it will be great.
When is such a condition? When eventual consistency is acceptable
In practice, you perform the processing at the speed of RAM and CPU and return the response to the user, and then process the operation at the opportunity (from here on, go like the pessimistic formula). Of course, in this case, your system actually suffers from eventual consistency, which is not a big deal in itself. Like short URL makers
- The user requests shortening
- Quickly generates a new ID (e.g. from Snowflake, UUIDv7, or HiLo)
- Puts it in Redis (SETNX or Hash) and immediately returns the short URL
- Sends a message to Kafka/RabbitMQ/Pulsar. (This pattern is called Transactional Outbox Pattern or Change Data Capture)
- Background job updates the database later
- p99 latency < 10 ms
- Near-linear horizontal scaling
3.transactional operation:
(update..output) capability in SQL (or any other automatic method provided by the database itself for this task. If not, handle this in code or use automatic execution on the database or a locking mechanism in coding such as semaphore
4.Optimistic change checking:
All processes can read the data simultaneously but cannot change it. And when changing, using changes rowversion We can find out that a change has already been made to the data, as a result of which the new change will encounter an error.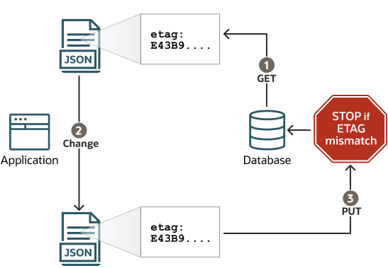
Use optimistic only when you are sure that
- Conflict (interference of simultaneous changes on a record) does not occur much
- In case of concurrency, there is no need for a retry system
- It is more used for conflict control in sync operations than async
- In distributed systems (multiple instances) + sharding is very difficult and sometimes impossible because version/checksum must be consistent in all shards or you use distributed lock which kills scaling.
In one sentence => best performance in high-throughput + low-conflict
Classic examples: Instagram like, GitHub star, cinema seat reservation, Wikipedia page editing
Now Formula
1) First, check if the processes are sync or if it is possible to process async
2) Second, decide according to the following formulas
If async was ok. You store the data raw in a table and return the response to the user and then lock and process it with a pessimistic+ SkipLocked job.
If you still need more speed, you store it in Redis and return the response to the user and transfer the information to the database as async and it continues like above
If async is not OK, the task becomes difficult.
In a situation where there is the ability to process in-memory and create the response, you perform the calculations and use Redis as a temporary database and everything can be done similar to the Redis technique that I mentioned in the previous step.
Note that wherever the name Redis appears, the operation must be atomic.
In the part where we are going to work with the database, use atomic oration or optimistic techniques (in case of low conflict)
Worst case possible: the operation must be sync and eventual consistency is not accepted:
We must work directly with the database facilities. In this case, local cache is useless and distributed cache can only be used with atomic operations (Lua script) or (Redis Transaction + WATCH or distributed lock) which itself has a cost.
Probably transactional operation and optimistic technique will be the most useful. Of course, for financial systems, you may even have to lock rows pessimistically.
Now if you have a question that it reduces throughput because the processing queue is formed and it will actually contradict the scale rules that were designed for simultaneous processing to increase speed
In answer I have to say: absolutely true. This is the worst possible case that there is no other way.
Here we have to go to methods like sharding or partitioning. We may even have to set up a replica of sync type. The only advantage of these things will be when reading data, which is probably 70% of the operations will be of this type, as a result we still benefit from the benefits of scaling