Implementing Stateful Services in a Horizontally Scaled Architecture

In modern cloud-native systems, managing state across multiple API calls can be tricky. Imagine an airline ticket purchase:
1. List flights & prices
2. Reserve a flight
3. Complete payment
If the price changes between steps, how do you ensure the user can still complete the process reliably?
Traditional 𝗦𝘁𝗶𝗰𝗸𝘆 𝗦𝗲𝘀𝘀𝗶𝗼𝗻𝘀 can help by routing a user to the same instance, but they come with drawbacks: tight coupling, failover risks, and uneven load distribution.
A more robust solution? 𝗦𝗵𝗮𝗿𝗲𝗱 𝗦𝘁𝗮𝘁𝗲 using Redis or NoSQL:
• Store temporary state on each API call
• Persist final state to the main database
• Handle concurrency with 𝗢𝗽𝘁𝗶𝗺𝗶𝘀𝘁𝗶𝗰 𝗟𝗼𝗰𝗸𝗶𝗻𝗴
• Ensure 𝗮𝘁𝗼𝗺𝗶𝗰 𝘂𝗽𝗱𝗮𝘁𝗲𝘀 using transactions or Lua scripts
• Use 𝗶𝗱𝗲𝗺𝗽𝗼𝘁𝗲𝗻𝗰𝘆 𝗸𝗲𝘆𝘀 to prevent duplicate operations
In large distributed systems, adding a 𝗖𝗼𝗿𝗿𝗲𝗹𝗮𝘁𝗶𝗼𝗻 𝗜𝗗 alongside state makes debugging and tracing end-to-end workflows much easier.
Proper TTL, failure handling, and atomicity ensure your solution is 𝘀𝗰𝗮𝗹𝗮𝗯𝗹𝗲, 𝗿𝗲𝘀𝗶𝗹𝗶𝗲𝗻𝘁, 𝗮𝗻𝗱 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻-𝗿𝗲𝗮𝗱𝘆.
How to Control Concurrency Without Killing Scaling? (Practical Formula)

Most developers analyze their system design by designing a system that keeps latency constant as throughput increases. Of course, this definition is correct, but the point is that in this regard, more attention is paid to the scaling category (focusing on horizontal scaling) and all the solutions offered are in line with this concern. And the point that always remains is the consistency and concurrency category. Many developers forget that for all software with a very serious and important problem that lurks like a hidden danger to seriously affect constancy and throughput. The name of the problem? concurrency
Now the point is that all the solutions proposed to solve this problem neutralize and make ineffective all or at least a large part of the measures taken to scale and increase throughput
But...
Wait
Is this really the case?
How I Make My Systems Scale
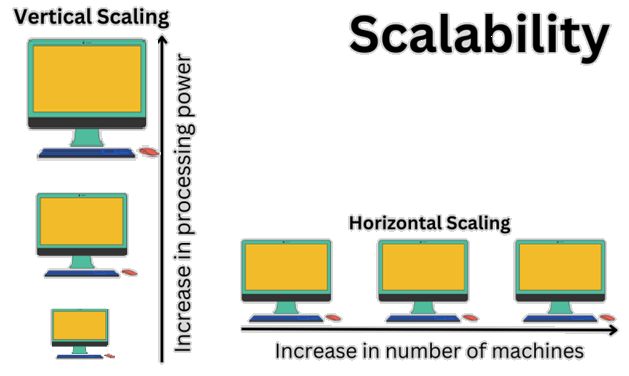
In this article , we provide a practical, step-by-step guide to making software systems scalable , from a single-server setup to a fully distributed architecture.
It begins with the fundamentals of I/O performance, explaining how hardware limitations such as disk speed and network latency affect system throughput. Then it explores progressive scaling strategies, including vertical and horizontal scaling, caching, asynchronous processing, and load balancing.
Finally, it addresses the deeper challenges of distributed systems . data consistency, CAP theorem, replication, sharding, and event-driven communication .
offering clear, real-world approaches for designing resilient, high-performance application